AI Models Excel in Math Olympiad: GPT-5.4 Leads with 95.24% Accuracy, Outpacing Human-Level Reasoning
March 29, 2026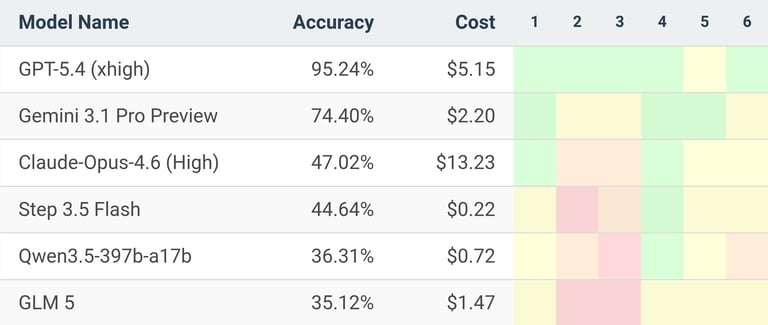
MathArena employed a semi-automated, three-model judging panel (GPT-5.4, Gemini 3.1 Pro, Opus 4.6) to score solutions, aiming to reduce self-bias and formatting bias, with human-review score shifts capped at two points.
The evaluation incurs notable costs: GPT-5.4 at $5.15 per run, Gemini 3.1 Pro at $2.20, Claude Opus 4.6 at $13.23, and Step-3.5-Flash at $0.22.
GPT-5.4 (xhigh) led the field with a 95.24% score on the 2026 US Mathematical Olympiad (USAMO).
GPT-5.4’s sole significant error occurred on Problem 5, where it produced an invalid counterexample and incorrectly argued the statement was false.
From 2025 to 2026, improvements include not only higher scores but also a shift in error types toward fewer circular arguments and incoherent proofs; remaining mistakes are subtler, such as occasional mid-proof chain-of-thought remnants.
The results indicate frontier AI is nearing expert-level mathematical reasoning, underscoring the pace of AI-driven breakthroughs in science.
Gemini 3.1 Pro finished second with 74.4%, followed by Claude Opus 4.6 at 47% and open-source Step-3.5-Flash at 44.6%.
Summary based on 1 source
Get a daily email with more AI stories
Source
OfficeChai • Mar 29, 2026
GPT 5.4 (xhigh) Scores 95% On 2026 US Math Olympiad, Gemini 3.1 Pro Second With 74%