NVIDIA Unveils Jet-Nemotron: Revolutionizing AI Efficiency with Hybrid Architecture
August 27, 2025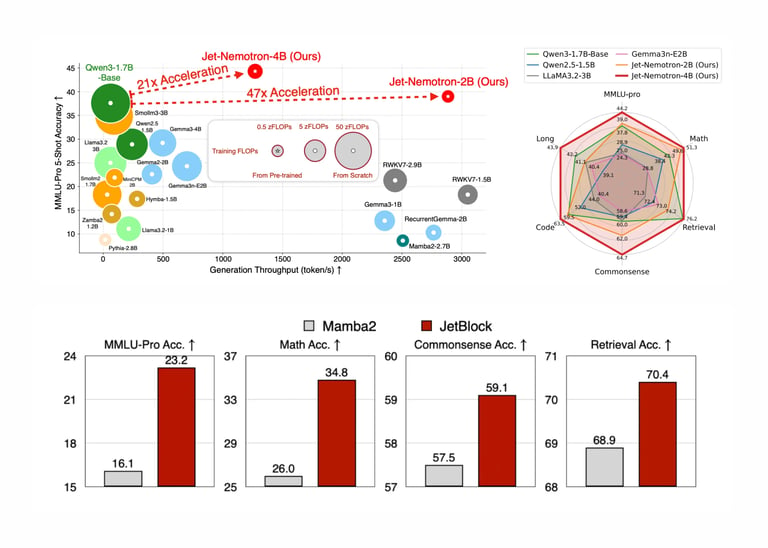
A new NVIDIA family, Jet-Nemotron, blends a hybrid-architecture for 2B and 4B models that delivers up to 53.6× higher generation throughput than leading full-attention LLMs while maintaining or exceeding accuracy.
The core method is Post Neural Architecture Search, which retrofits pre-trained models by freezing MLPs and replacing Transformer attention with JetBlock, a hardware-efficient linear attention block guided by a hardware-aware search.
JetBlock introduces dynamic causal convolution kernels conditioned on input and cuts redundant convolutions to boost efficiency without sacrificing accuracy.
Key performance figures show Jet-Nemotron-2B hitting 47× throughput with a 154MB KV cache, and Jet-Nemotron-4B hitting 21× throughput with a 258MB cache, with competitive or superior benchmarks such as MMLU versus Qwen3-1.7B-Base.
At scale, inference cost drops by about 98% for the same token volume, memory footprints shrink dramatically, and the architecture is better suited for edge deployment on devices like Jetson Orin and RTX 3090.
NVIDIA outlines clear use cases for business leaders seeking cost savings and scalability, practitioners aiming for edge deployment without retraining, and researchers pursuing lower-cost architecture innovation and faster iteration.
Jet-Nemotron and JetBlock will be open-sourced, with PostNAS presented as a general framework to accelerate Transformer efficiency, including links to the arXiv paper and GitHub resources.
Summary based on 1 source
